

[POLICY BRIEF] Digital Commons as Alternative Systems of Value, by Louise Frion
15 June 2023
[STUDENT ESSAY] In the Age of Tech Giants, Is Meta on a Treacherous Path?
27 June 2023
This article presents two research projects led by two groups of students from the Digital, New Technology and Public Policy stream of the Master in Public Policy and Master in European Affairs of the School of Public Affairs, as part of the course entitled “Decoding biases in artificial intelligence” given by Jean-Philippe Cointet and Béatrice Mazoyer. This course invites students to explore the issues of discrimination in AI and to get their hands on data and code to investigate a public policy question of their choice.
First project: Uncovering the algorithmic biases in foster parent-child matching algorithms
In the United States, there are over 400,000 children in foster care, with over 200,000 children entering and exiting each year. In order to maximize their limited resources, some Child Welfare Departments have begun experimenting with algorithmic tools to assist social workers with decision-making, such as predicting risk of maltreatment, recommending placement settings, and matching children with foster parents who are able to accommodate their unique needs. While some tools have been commended by researchers for their improvements to child-outcomes and cost reductions, other analyses skepticize that the tools are biased, difficult to explain, or opaque. In our report, our group set out to uncover whether unfair treatment of minority children is perpetuated or systematized by AI-enabled placement algorithms.
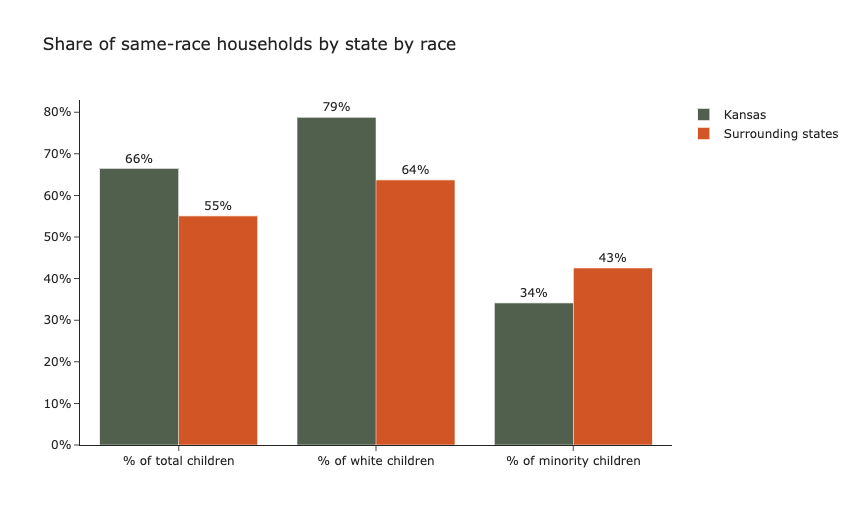
Preliminary research suggested that the placement of children in same race households has a significant positive effect on children’s long-term wellbeing. However, unfair treatment of minority children in placement algorithms can threaten the wellbeing of this particularly vulnerable group. To test whether this is the case, our project examined whether minority children are equally as likely to be placed in same race households as white children. For the analysis, we used the Adoption and Foster Care Analysis and Reporting System 2015 (AFCARS) data set, a comprehensive and extensive data set compiled by the Children’s Bureau (CB) within the Administration for Children and Families (ACF) in the United States. We leveraged racial demographic data to examine foster care placements in Kansas, one of the first US states to adopt AI-based matching, comparing it with its neighboring states Nebraska and Colorado, which were not using such tools in 2015. This decision was made to eliminate as much as possible the variability of the different states’ characteristics. Using this methodology, we explored the following research questions:
- Is there racial overrepresentation among foster families?
- Is AFCARS representative enough to be used as a training data set?
- Are states that use placement recommendation models or child-foster parent matching models more likely to consider children’s wellbeing by placing them in same-race households?
When examining the demographic composition of foster care placements in aggregate, it appeared that foster children in Kansas were 11 percentage points more likely than in surrounding states to be placed in same-race households. However, sub-group analysis uncovered a more confounding finding: minority foster children in Kansas are 8 percentage points significantly less likely to be placed in same-race households, while White foster children in Kansas are significantly more likely to be placed in same-race households. On the one hand, it was reassuring that a system using algorithmic matching is significantly more likely to place children in same-race households in aggregate. On the other hand, a system using algorithmic matching significantly diminishes the likelihood of a minority foster child being placed in a home that generates long-term positive outcomes. As minority foster children are a particularly vulnerable subpopulation, the results suggest that algorithmic matching may disproportionately disadvantage a group that is already systematically disadvantaged.
Through this research we aimed to inform future research on unbiased decision-making tools used in the foster care placement procedures, which will be the main form of assistance for the authorities that are working diligently to protect and provide the best possible outcomes for vulnerable children. In doing so, more advanced matching algorithms can prevent underlying biases that favor white children over minority children.
Authors : Stavroula Chousou, Yasmine El-Ghazi, Ludovica Pavoni, Lea Roubinet & Morgan Williams
Second project: Biases behind image-generative algorithms
From AI art to deep fakes, image-generative algorithms are emerging in discussions that span culture, philosophy and politics.
A frequent example – also taken up in our paper – is Stable Diffusion, launched in 2022 by Stability AI. Following the footsteps of Open AI’s DALL•E, it is a model capable of generating images from text descriptions. The way this works is through so-called Generative Adversarial Networks (GANs), a generative model that builds on noise-contrastive estimation to enable a system to distinguish data from noise. More specifically, Stable Diffusion is trained on a total of 2.3 billion image-text pairs, and uses a latent diffusion model (LDM), a less computationally expensive alternative to the methods employed in DALL•E but which allows to retain the quality and flexibility. This is very much in line with Stability AI’s approach to AI development which, as opposed to OpenAI’s, is open source. This means that users can access the code, the weights, create forks and, all in all, use Stable Diffusion with few compulsory safety measures. And it is because of this that we decided to test how StableDiffusion could shape a different way of engaging with algorithmic bias. In fact, integral to the discussion around generative AI are questions about bias and fairness, most often exemplified as racial or gender based biases.
Our research looked at Stable Diffusion’s biases with a twist, exploring biases which were not as extensively studied in the academic literature: religion and culture. How would Stable Diffusion image generation system handle religion?
To test this we conducted a qualitative analysis based on eight religions or religion-related categories – Christianity, Islam, Hinduism, Buddhism, Sikhism, Judaism, Shintoism, and Atheism – with the prompt “A photo of the face of ___” followed by a gender-neutral term for a follower of each selected religion. First, we found that the images Stable Diffusion generated display a wide range of stereotypes and are particularly prone to amplify them. For instance, the correlation between masculinity and religion is prevalent in the AI’s output – with the only feminine features generated were in samples representing Islam and Hinduism. In this regard, we also found that the images over-estimate religious symbolism. Hindus (male and female) have Bindis and/or additional decorative jewelry on their foreheads, all Sikhs are wearing turbans, and all humanly portrayed Buddhists resemble monks (“humanly portrayed Buddhists” to distinguish from the Buddhist statues that Stability AI also generated). As we claim, the model draws on ‘unambiguous’ portrayals of religion even without being prompted to. We speculate that this may amplify backwards and underdeveloped impressions of these religions.
On a more positive note, the images do not display commonly held negative stereotypes against some religions – something especially clear in the case of Muslims which are often displayed in media coverage of terrorist events which could have drawn a link between Islam violent behavior. In terms of ethnicity, most religions were represented by their majority cultural origin.
We then looked at “complex bias”, testing how the model associated certain religious groups with a particular set of backgrounds, attitudes or circumstances. The way we did this was by modifying the initial prompt with specifications of time period or gender. This was apparent in the case of Judaism, where the pictures it generated distinctly resembled early 20th century monochrome portrait photographs, lacking full color and including outdated fashion and posing. This contributes to the “historicization” of the religion which has however been rejected by various Jewish organizations as reductive. Other such biases which draw on “pernicious assumptions and power relations” are analyzed more in depth in the paper.


All in all, our findings point to a Western bias that generates representational harms for religious minorities in the West, including misrepresentations and disproportionally worse performance. While Stability AI’s focus on transparency is of crucial importance, unbiasing the foundational data at pre-processing level needs to become of primary concern. This means developing ‘data statements’ and ‘data sheets’ to increase transparency of the databases and their architecture to make bias easier to study and address. Such a practice can allow the data curator to summarize and motivate the dataset’s characteristics and creation methods. This would also fit in Stability AI’s wider approach to AI. In fact, enshrining openness as Stable Diffusion’s core value has impactful consequences on how Stability AI views bias: the belief is that, while Stable Diffusion may indeed perpetuate bias, in the long term, the community-based approach will produce a net benefit. Data statements would be a good way to allow for more cooperation within that community.
Authors : Barbora Bromová, Giovanni Maggi, Christoph Mautner Markhof, Riccardo Rapparini, Laura Zurdo