Partager les données de la recherche
Partager les données de la recherche
")
 Image Mircea Moira (via Shutterstock)
Image Mircea Moira (via Shutterstock)
La question du partage des données de la recherche est depuis plusieurs années devenue centrale dans le monde académique. Pour encourager la transparence, l’intégrité scientifique, la mise en partage et la ré-employabilité des données, les chercheur‧es sont encouragé‧es à rendre accessibles les données de leurs recherches. Mais quelles sont les conséquences de cette pratique ? Comment la mettre en place concrètement ?

Célia Bouchet est post-doctorante au CEET (Centre d'études de l'emploi et du travail) du CNAM. Ses recherches, menées notamment au CRIS et au LIEPP (au sein de l'axe Discriminations et Politiques catégorielles), portent sur les mesures et les mécanismes des inégalités sociales, notamment celles liées au handicap et au genre. Depuis la soutenance de sa thèse, elle a largement contribué à disséminer ses résultats de recherche, en facilitant l'accès à ses données. Elle est lauréate du Prix de thèse du Défenseur des Droits 2023 et du Prix science ouverte des données de la recherche 2023, remis par le Ministère de l’Enseignement Supérieur et de la Recherche.
- Aviez-vous dès le départ de votre travail de thèse l'idée de conserver, documenter, permettre une réutilisation de vos données ?
Non, je pense que cette idée est venue parce que je n’avais pas vraiment de modèles d’ouvertures de données de thèse à disposition. Je n’ai pas été formée à la mise à disposition des données lors de mon master. J’avais plutôt des réflexes de protection des données allant à l’encontre d’une ouverture : protéger l’anonymat des personnes rencontrées en entretien, respecter l’engagement de non-partage des données passé avec l’Adisp (Archives de Données Issues de la Statistique Publique, qui gère la mise à disposition des enquêtes de la statistique publique). Cela étant, c’est une idée qui est arrivée tout de même assez rapidement, au bout d’un an de thèse environ, par deux intermédiaires différents. D’abord, j’ai participé à une formation de l'École de la recherche sur la gestion des données de la recherche, où cette question du devenir des données à l’issue de la recherche était évoquée. Ensuite, au moment du lancement de ma campagne d’entretiens quelques mois plus tard, ma directrice de thèse, Anne Revillard, m’a conseillé de profiter de la fiche d’information que je comptais distribuer aux personnes interrogées afin d’obtenir leur accord explicite pour que d’autres chercheur‧es puissent réutiliser les entretiens. Ces deux influences ont eu un rôle important.
- Est-ce que du personnel support vous a accompagnée dans la gestion de ces données ?
J’ai pu m’appuyer sur plusieurs collègues des équipes de soutien à la recherche. Cyril Heude, data librarian à Sciences Po, s’est rendu disponible pour créer mon compte sur Data Sciences Po, répondre à mes questions, émettre des suggestions, et publiciser mes jeux de données avec Guillaume Garcia, ingénieur de recherche au CDSP de Sciences Po. Paul Colin, anciennement responsable de la gestion et de l’ouverture des données pour le PPR Autonomie, m’a aussi conseillé lorsque j'ai commencé à rédiger un article méthodologique sur mon travail d’ouverture des données. Enfin, deux déléguées à la protection des données de Sciences Po, Marion Lehmans puis Nawale Lamrini, m’ont accompagnée pour garantir la conformité de ma recherche doctorale et du processus d’auto-dépôt au cadre réglementaire.
Légende: Page d’accueil de data.sciencespo, l’entrepôt de données de Sciences Po
- Aujourd’hui, comment gérez-vous les données de recherche que vous produisez ?
.png)
Légende: Page d’accueil du carnet Hypotheses de Célia Bouchet.
URL: https://celiabouchet.hypotheses.org/
- En tant que jeune chercheuse, comment vivez-vous le contexte croissant d’incitation à l’ouverture des données de la recherche ?
- Quels aspects vous semblent poser problème ?
- Est-il chronophage pour vous de préparer ces données ? Comment articulez-vous ce travail avec votre temps de recherche ?
C’est un travail d’une ampleur que je n’imaginais pas. Pour contextualiser, j’ai mis en ligne deux jeux de données : un jeu centré sur les matériaux qualitatifs de ma thèse, notamment les transcriptions d’entretiens, la fiche d’information que j’ai transmise aux personnes rencontrées, la grille d’entretien, etc ; et un jeu centré sur une exploitation statistique de l’Enquête emploi en continu, réalisée dans le cadre du volet quantitatif de ma thèse. Pour le volet qualitatif, comme je récoltais mes propres données, il a fallu beaucoup d’anticipation et de formalisation. Pour le volet quantitatif, j’ai pris la décision plus tard et j’avais davantage de marge de manœuvre. Mais dans les deux cas, cela impliquait un gros travail : changer tous les noms propres sur 1400 pages d’entretiens (pour une pseudonymisation renforcée) ; trier et nettoyer mes scripts de code, puis ajouter des explications didactiques au fur et à mesure ; déterminer les autres documents méthodologiques pertinents et les mettre en forme ; documenter tout ce processus dans des fichiers Read-Me… Cela m’a pris plusieurs centaines d’heures au total. Comme j’avais un contrat de recherche en journée, sur un projet différent, je prenais ce temps sur mes pauses déjeuners, mes soirées, mes week-ends. Je l’ai vécu comme long et fastidieux, et je n’encouragerais pas nécessairement quelqu’un d’autre à se lancer dans ces conditions.
- Avez-vous été confrontée à d’autres obstacles liés au partage de données ?
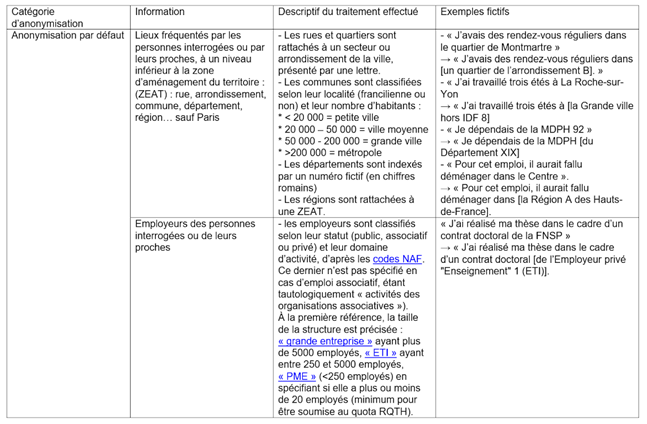
- Vos jeux de données facilitent-ils d'après vous la valorisation de vos travaux ?
Oui, mais de façon indirecte. J’ai été frappée par l’intérêt qu’a suscité mon travail d’auto-dépôt, davantage peut-être que les données déposées. J’ai été invitée à plusieurs reprises pour présenter ce processus d’ouverture des données : lors de la semaine DataSHS 2022, dans le cadre d’un séminaire CIVICA Open Science… J’ai aussi publié un article méthodologique dans la revue Genèses, où j’analyse mon expérience d’auto-dépôt. Ce sont de belles opportunités. En revanche, je n’ai pas connaissance de projets de recherche en cours qui envisagent de réutiliser mes données. Et je peux le comprendre, car on n’apprend pas vraiment à utiliser ce type de sources lors des formations en sciences sociales.
- Vous êtes lauréate du Prix science ouverte des données de la recherche 2023, pour votre Projet « EHDS: Enquête Handicap et destinées sociales ». Qu’est-ce que le jury a récompensé selon vous ?
_0.png)
Tracés, 2019, numéro spécial 19, “Les sciences humaines et sociales au travail (ii): Que faire des données de la recherche ?” DOI: 10.4000/traces.10518
Genèses, 2022, numéro 129, “Le procès des données”. DOI: 10.3917/gen.129.0003
Propos recueillis par le Centre de Recherche sur les Inégalités Sociales et le Laboratoire Interdisciplinaire d'Evaluation des Politiques Publiques de Sciences Po.
Publié dans la collection des Entretiens, notes & analyses du LIEPP
EN SAVOIR PLUS :
BENDJABALLAH Selma, GARCIA Guillaume, CADOREL Sarah et al., « Valoriser les données d’enquêtes qualitatives en sciences sociales : le cas français de la banque d’enquête beQuali », Documentation et bibliothèques, 2017/4 (Vol. 63), p. 73-85
BOUCHET, Célia. « Comment j’ai déposé les données de ma recherche (sans savoir ce qui m’attendait) » Genèses, 2023/4 (Vol 132), p. 113-129.
BOUCHET, Célia. Rendre accessible et visibiliser ses données et ses codes : retours sur une expérience d'entreposage. Semaine Data-SHS. Traiter et analyser les données quantitatives en sciences humaines et sociales 2022, Plateforme Universitaire de Données des Grands Moulins; Université Paris Cité; Centre de Données Socio-Politiques, Dec 2022.
LEPRINCE, Chloé. Butin à monnayer ou manne à partager : avec les données, les chercheurs peuvent-ils faire feu de tout bois ?, France Culture, 2023.
REBOUILLAT, Violaine. Ouverture des données de la recherche : de la vision politique aux pratiques des chercheurs. Sciences de l'information et de la communication. Conservatoire national des arts et metiers - CNAM, 2019.
REVELIN, Florence, LEVAIN, Alix, MIGNON, Morgane, NOEL, Marianne, QUEFFELEC, Betty, et al.. L'ouverture des matériaux de recherche ethnographiques en question. Rapport d'enquête du projet "Partage et protection des données qualitatives à l’ère du numérique : expériences, enjeux, stratégies". Rapport de recherche. Centre national de la recherche scientifique. 2021.
Guide thématique, Données de la recherche : suivez le guide, Bibliothèque de Sciences Po
Guide thématique, Qu’est ce que la science ouverte ?, Bibliothèque de Sciences Po
Guide thématique, Actualités de la science ouverte, Bibliothèque de Sciences Po
Guide thématique, Demande des bailleurs de fonds pour les projets financés, Bibliothèque de Sciences Po
Plus d’informations sur l’entrepot de données Nakala : https://www.nakala.fr/about