
Home>When political science embraces big data


25.09.2025
When political science embraces big data
Computational social sciences (or CSS)? Behind this expression lies a set of methods and IT tools that enable researchers to leverage the vast amounts of data available online to answer questions in the social sciences. Whether you are looking to create large-scale datasets or automate their analysis, there is something for everyone. And while these methods require knowledge of R or Python, they are not reserved for data scientists with a background in computer science: they are becoming increasingly accessible, and even researchers who favour qualitative approaches can benefit from them to facilitate part of their work, as Meryem Bezzaz, Malo Jan, Selma Sarenkapa and Luis Sattelmayer, PhD candidates at the CEE, demonstrate in this interview. All four are using these methods in their PhD theses and they have organised a doctoral workshop devoted to the use of computational methods in the study of political competition. Malo and Luis also shared their knowledge in an inter-semester course at Sciences Po's School of Research, which attracted around twenty of their colleagues from master's and doctoral programmes in economics, history, political science and sociology.
How do computational methods help you in your research?
Meryem Bezzaz: I am interested in the framing of European energy policies by what is known as the energy trilemma: reconciling security of supply, affordability and environmental objectives. I use R to download large quantities of public documents available online: reports produced by various actors, as well as legislative texts (EU directives, regulations, etc.) on European energy policies. Next, I clean them up (convert PDFs to text files, remove images, etc.) and transform them into data (depending on the case, the unit of analysis can be words, sentences or paragraphs): I create a text database so that I can then analyse it. The next step will be to look for certain keywords, links between the three concepts of the trilemma, but also changes in framing over time and trends according to the types of authors and documents: can we deduce differences in terms of political priorities? This aspect is only part of my thesis: I have also conducted interviews with the people who produced these documents.
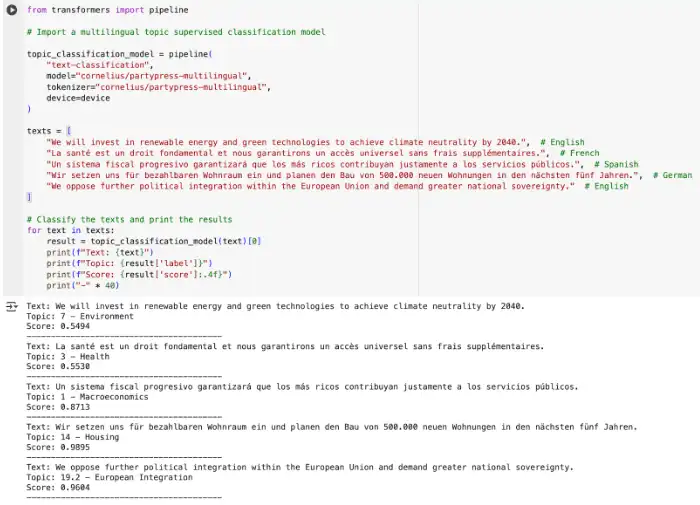
Malo Jan: I am also using CSS techniques to collect and analyse data for my thesis, whose focus is on the evolution of partisan competition on climate issues. In other words, how political parties position themselves on climate issues today compared to a few years ago, in different European countries. To do this, Luis and I collected party communications in a dozen European countries: social media posts, parliamentary speeches, press releases, etc. We're talking about millions of texts in different languages. The next step is to identify, among all these texts, those that deal with environmental and climate issues. For this, I use machine learning: in a small sample of texts, I manually define (or annotate, or code) which texts deal with climate-related issues and which do not. Next, I train a natural language processing (NLP) model that will be able to replicate the decisions I have made. Once the model is working well, it allows me to see to what extent the parties address the issue of climate change in their publications. And then, within this subset, I can more accurately measure party positions: I try to identify different types of discourse on climate issues, for example opposition to or support for climate policies. These new methods give us the means to measure things that we couldn't measure before.
Luis Sattelmayer: For my part, I do similar things, but on immigration. I am interested in how mainstream parties in Europe engage with this flagship topic of the far right. To do this, I work on the corpus built jointly with Malo (PartySoMe, Party Social Media). I then seek to determine whether the positions taken by mainstream parties on immigration can explain their electoral decline. To do this, I incorporate the measurement obtained (i.e. a position that is more or less favourable to immigration) into an inferential statistical model.
Selma Sarenkapa: For me, the first step was to collect newspaper archives from two countries, Germany and France (approximately three million articles published in 12 newspapers since 1995). After cleaning up the corpus, I trained a model to automatically detect and classify certain social groups such as women, immigrants and investors. In a second step, I seek to find out how these groups are portrayed in the media: are they mentioned in a positive or negative light? And in what context (what topics do the articles cover)? For this step, it may be necessary to switch back and forth between unsupervised and supervised approaches [see box]: first see what themes the model proposes unsupervised, and whether they make sense, and if not, return to a supervised approach.
Machine learning analysis involves using computer models to automatically analyse texts. It can be classified into two categories depending on when the researcher intervenes in the interpretation (in other words, depending on the type of data provided to the model, labelled or unlabelled). The field has progressed in recent years thanks to the emergence of large language models (LLMs) such as BERT and GPT, which are pre-trained with very large numbers of texts. These models, developed for generic use, can then be adjusted for a specific analysis task (fine-tuning).
Supervised methods
This category of machine learning consists of having an algorithm reproduce analyses based on training data provided by the researcher. This may involve training a model to classify units (e.g. sentences in an article, bill titles, etc.) according to a criterion considered relevant to answer a research question. A sample of the manually categorised corpus is used by the model to learn which characteristics of the text correspond to which categories, in order to then deduce the categories of other texts. After adjustment steps (validity tests followed by an increase in the number of manually processed cases if a subject is poorly predicted by the model), the model(s) can annotate the entire corpus. Sentiment analysis is an example of the use of a supervised classification model where the category to be predicted is the type of sentiment.
At the CEE, in addition to the theses discussed in the main text, these methods are practised by Emiliano Grossman within the Comparative Agendas Project to code the themes addressed in party manifestos (he pioneered the approach with others), and also as part of the UNEQUALMAND project, led by Isabelle Guinaudeau and involving Selma Sarenkapa. In a recent article, Ronja Sczepanski and a colleague propose a tool for automatically detecting and extracting references to social groups in political texts.
Elena Cossu, together with Jan Rovny and Caterina Froio, uses these types of methods to analyse neo-authoritarian and illiberal ideological dynamics at the European Union level, both among elites and politicised citizens (AUTHLIB project). They rely in particular on supervised BERT models to automatically categorise tweets, election manifestos and party press releases, with the aim of identifying and comparing discursive expressions of illiberalism. Caterina Froio also uses them as part of the FARPO project to automatically identify and code protests involving far-right actors. The RESPOND project, supervised at the CEE by Cyril Benoît and involving Sebastian Thieme, involves large-scale scraping of government websites and algorithms for classifying laws. Similarly, the KNOWLEGPO project (Matthias Thiemann and Jérôme Deyris) required the extraction of large amounts of online text, followed by the use of LLM to classify the ways in which Federal Reserve members present the causes of inflation or fiscal policy in their deliberations and speeches.
Unsupervised methods
The objective is also to classify units into different categories, but the approach is inductive rather than deductive. Language models propose clusters based on similarities/dissimilarities in language between several units, without the user determining in advance what to look for.
For example, Selma Sarenkapa tries to bring out themes from the data without any preconceptions rather than imposing them (topic modelling): she provided a model with sentences mentioning specific social groups in order to obtain a list of themes. She then grouped these themes together to create a more restricted list of themes specific to each group, which she was able to use to train (in a supervised manner) a new model. Jérôme Deyris uses similar methods to explore the different ways in which central bankers talk about climate change in their public speeches.
Elena Cossu, together with Jan Rovny and Caterina Froio, as part of the AUTHLIB project, also uses unsupervised approaches, such as automatic annotation by large language models (e.g. LLaMA), to extract and structure discursive categories related to illiberalism directly from the data, without resorting to prior manual coding.
At the end of 2024, you organised the CEE's annual doctoral workshop, whose title was Using computational methods to study political competition. Why did you choose this topic? What did you learn from it?
Selma: We realised that several of us were using fairly similar methods. So, the idea was to meet other doctoral students from different universities who also employ these approaches to study topics related to political competition and polarisation in political communication, on social media, in traditional media, and in public policy. The aim was to facilitate a productive exchange of ideas on each other's doctoral work.


Luis: We invited doctoral students we already knew and others we didn't know yet: this is a way to create a network. It also allowed us to spread the word that there is a whole group of people at Sciences Po who are interested in Computational Social Sciences, including of course the medialab [represented at these days], but not only.
Meryem: Beyond the thesis presentations, which showed different methods at different stages of progress and raised different questions, I also enjoyed the discussions with senior researchers such as Alex Kindel (medialab), who reminded us of the importance of constructive validity (the ability of a model to reflect what it is supposed to measure) and predictive validity (the ability to predict future results). Jan Rovny emphasised the importance of a solid theoretical foundation, and Ronja Sczepanski spoke about publishing in computational social sciences.


Malo and Luis, in January and June you gave a 1-week course on Computational Social Sciences to fellow graduate students, which was very successful. What was your objective in setting up this course? What did the students who took it learn?
Malo: The aim of this course was to train students with basic knowledge of programming to go a little further than what is covered in the master’s programme. Luis and I trained ourselves, but we think this is something that should be part of research training at Sciences Po these days. Over the course of a week, we provided an overview of CSS techniques. We demonstrated how to start from a research question, what can be measured in texts, how to build a corpus and how to collect data online. We also covered the latest advances in analysis, including what artificial intelligence and large language models (BERT, ChatGPT, etc.) can offer. Each day, we covered a different type of method: supervised methods, unsupervised methods [see box], how to convert textual data into digital representation so that it can then be processed using statistical methods, etc.


Luis: We structured the course into three sessions each day: a first session on theory, a second session demonstrating examples of computer code, and a third session for students to practise using practical cases that we had prepared. For example, we asked them to annotate texts collaboratively, with 20-30 texts to code each, which were then used to train a model to show them how it works.
The advantage of this one-week format is that students left with a comprehensive understanding of the different concepts and methods, their advantages and disadvantages, and scripts that they can reuse. But such an intense week does not necessarily leave participants enough time to develop their projects. A number of them either come with projects in mind or realise during the week what they could do with these methods in relation to their research interests. Offering a semester-long course would allow for better support for these projects.
In any case, it was a pleasure to see such enthusiasm (we even had to create a waiting list at one point). This shows that there is a real demand, in addition to the two courses on R that we each taught in the first and second semesters of the master’s programme respectively.

Are there any limitations to computational analysis?
Luis: These methods are less effective for certain tasks: if we are trying to measure a concept that is difficult to explain (and difficult to detect systematically, even by humans), no matter how advanced and sophisticated the method may be, it will not work. If we choose a supervised method, the concept we are interested in must be well defined.
Malo: Supervised methods are useful to measure social science concepts in large data sets. The advantage really comes with the volume of data, because the goal is to automate something that would take much longer if done manually from start to finish. So, we also need to ask ourselves whether our data volume is sufficient to warrant this type of method.
In fact, the question is one of available time and the level of commitment we are willing to put into such a task, and the answer varies from person to person. A senior researcher with a substantial budget could pay 30 research assistants to analyse 50,000 texts manually. But as I am a PhD student with limited time to write my thesis and no one to work for me, the trade-off is different.
Are there any other precautions that need to be taken?
Luis: There are ethical issues, but these are the same ones that other colleagues handling other types of data also face: where is the data stored? Depending on the nature of the data collected, can we entrust it to OpenAI or Google servers, or should we do it locally, on our own machines?
Malo: On the other hand, a distinctive feature of most of the data we process using these types of methods is that it was not originally produced for research purposes. Of course, we collect and format it so that we can analyse it, but we are not the source. Unlike qualitative interviews or surveys, where respondents know that it is for research purposes and give their consent, we collect texts and data that are produced for a completely different purpose than the one for which we use them. When it comes to data from applications, we did not ask the people using these applications if they agreed to their data being made available in a particular format. This raises questions in terms of making the data available [to the rest of the academic community] and the replicability of the research.
Luis: Finally, the use of large language models has significant energy costs and environmental impacts.
Artificial intelligence and machine learning are rapidly evolving fields: how do you see the future of computational social sciences? And are you seeing any changes in your corpus, as a result of the increased use of generative AI in content creation?
Meryem: The question makes me think of a recent study that Étienne Ollion (sociologist, CNRS research professor) presented during our workshop. With colleagues, he answered the question: "Can generative AI imitate humans in responding to opinion polls?" What they show is that the answers provided by ChatGPT-type bots are biased, and that this bias varies depending on the topics covered.
Malo: The most recent advances concern the processing of audio or images, or even what is known as multimodal data (simultaneous analysis of images and audio or text). For example, if we want to analyse parliamentary debates, it may be useful to collect not only the content of the speeches, but also the gestures, tone of voice, etc.
Meryem: Beyond audio and images, will the use of generative AI influence texts, sources and corpora, with perhaps more standardised language? Now that analysis tools are becoming more widely available, will documents become easier to extract and analyse, or will certain players make data more difficult to obtain or monetise access to it?
Luis: If models are trained on texts created by ChatGPT, which are not always of good quality, these models may lose performance. We could see a vicious circle emerge: AI-generated content, on which AI models are trained to create other content, and so on.
Finally, what advice would you give to people who want to get started in computational social science?
Malo: All the tasks we've mentioned (scraping, data cleaning, analysis) must be coded. So, at some point, you have to get your hands dirty, so to speak. But with a basic level of statistics and some programming skills, you can quickly understand the main methods and how to use them. And now, tools like ChatGPT can also help generate code. Of course, you still have to know how to use it, understand what it's telling you and to what extent it's what you want. But compared to 2-3 years ago, the cost of entry has fallen significantly.
Selma: These methods are also becoming more and more accessible because more and more people are sharing what they do [for example on GitHub and HuggingFace – see end of article], offering training, publishing scientific articles on their methods, like Ronja Sczepanski here: so it's becoming easier to understand how it works.
Luis: Even if you want to analyse manually and not do quantitative analysis, it is possible to automate everything upstream of the analysis, particularly large-scale data collection: instead of manually downloading a thousand PDF documents from a website, a script written in two minutes can do it in a single operation. Similarly, tedious copy-and-paste tasks can be automated. For people who conduct interviews and have to transcribe them, there are also AI-based automatic transcription tools, such as Whisper or Notta. There are more and more softwares, making these methods much more accessible.
Interview by Véronique Etienne.
Thanks to Meryem Bezzaz, Malo Jan, Selma Sarenkapa and Luis Sattelmayer for their time, as well as Yuma Ando and Isabelle Guinaudeau for their explanations and proofreading.
Find out more
- Programme of the workshop “Using computational methods to study political competition” (December 2024)
- Inter-semester course on Computational Social Sciences
- Github pages of Malo Jan, Luis Sattelmayer, Selma Sarenkapa
- HuggingFace pages of Malo Jan, Luis Sattelmayer, Selma Sarenkapa
People and projects at the CEE using machine learning
- People: Yuma Ando, Elena Cossu, Jérôme Deyris, Caterina Froio, Isabelle Guinaudeau, Emiliano Grossman, Ronja Sczepanski
- Projects : AUTHLIB, KNOWLEGPO, RESPOND, UNEQUALMAND
At Sciences Po, beyond the CEE :
- MetSem, a methodology seminar co-organised by engineers from various Sciences Po research centres (including Yuma Ando from the CEE)
- MetAt, a monthly workshop providing support for research methods, coordinated by engineers from the medialab
- The Open Institute for Digital Transformation, one of its focus being digital traces for the social sciences.