
Accueil>Quand la science politique s’empare des données massives


18.06.2025
Quand la science politique s’empare des données massives
Sciences sociales computationnelles ? Derrière cette expression se cachent un ensemble de méthodes et d'outils informatiques permettant de tirer parti des grandes quantités de données accessibles en ligne pour répondre à des questions de recherche en sciences sociales. Que l’on cherche à créer des corpus à grande échelle, ou à automatiser leur analyse, il y en a pour tous les goûts. Et si ces méthodes demandent de manipuler les langages R ou Python, elles ne sont pas réservées aux data scientists dotés d’une formation en informatique : elles se démocratisent de plus en plus et même les chercheurs et chercheuses se réclament plutôt d’approches qualitatives peuvent en tirer profit pour faciliter une partie de leur travail. Démonstration dans cette interview avec Meryem Bezzaz, Malo Jan, Selma Sarenkapa et Luis Sattelmayer, doctorantes et doctorants du CEE, qui les utilisent dans leurs thèses respectives et ont organisé des journées d’études doctorales consacrées à l’utilisation de méthodes computationnelles dans l’étude de la compétition politique. Malo et Luis transmettent aussi leurs connaissances lors d’un cours intersemestre à l’École de la recherche de Sciences Po, qui a attiré cet hiver une vingtaine de leurs collègues de master et doctorat en économie, histoire, science politique et sociologie, et qui est reconduit cet été.
À quoi vous servent les méthodes computationnelles dans vos thèses ?
Meryem Bezzaz : Je m’intéresse au cadrage des politiques énergétiques européennes par ce qu’on appelle le trilemme énergétique : concilier la sécurité des approvisionnements, un prix abordable et les objectifs environnementaux. J’utilise R pour télécharger en masse des documents publics disponibles en ligne : des rapports produits par les acteurs qui m'intéressent, ainsi que des textes législatifs (des directives, des règlements, etc.) sur les politiques énergétiques européennes. Ensuite, il s’agit de les nettoyer (transformer les PDF en fichiers texte, supprimer les images, etc.) et de les transformer en données (selon les cas, ces données sont des mots, des phrases ou des paragraphes) : je crée une base de données textuelles pour pouvoir ensuite l’analyser. La prochaine étape sera de chercher à détecter la présence de certains mots-clés, les liens entre les concepts du trilemme, mais aussi l’évolution du cadrage au cours du temps, les tendances selon les types d’auteurs des documents : est-ce qu’on peut en déduire des différences en termes de priorités politiques ? Cet aspect n'est qu’une partie de ma thèse : j’ai aussi réalisé des entretiens avec les personnes qui ont produit ces documents.
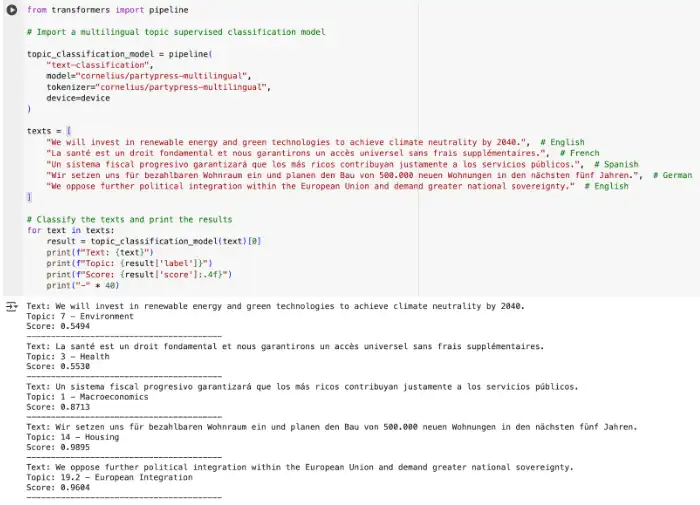
Malo Jan : Je fais aussi à la fois de la collecte et de l’analyse de données pour ma thèse. Celle-ci porte sur l'évolution de la compétition partisane sur les enjeux climatiques ; autrement dit : comment les partis politiques se positionnent sur les questions climatiques, aujourd'hui par rapport à quelques années en arrière, et ceci dans différents pays européens. Pour cela, avec Luis, nous avons collecté leurs communications dans une dizaine de pays européens : posts sur les réseaux sociaux, discours parlementaires, communiqués de presse, etc. On parle de millions de textes, dans différentes langues. L’étape suivante, c'est de réussir à identifier, parmi tous ces textes, ceux qui traitent des questions environnementales et climatiques. Pour faire cette classification, j’utilise le machine learning : sur un petit échantillon de textes, on va définir (annoter ou coder) que tel texte parle de climat, tel texte n’en parle pas. Ensuite, on va entraîner un modèle de Natural language processing (NLP) qui va être capable de répliquer les décisions qu'on a prises. Une fois que le modèle fonctionne bien, cela nous permet de savoir à quel point, parmi tout ce qu'ils publient, les partis abordent le sujet du climat. Et ensuite, dans ce sous-ensemble, de mesurer de façon plus précise les positions des partis concernés : peut-on identifier différents types de discours sur les questions climatiques, par exemple d’opposition ou de soutien aux politiques climatiques ? Ces nouvelles méthodes nous donnent des moyens de mesurer des choses qu’on ne pouvait pas mesurer avant.
Luis Sattelmayer : Pour ma part, je fais des choses similaires, mais sur l'immigration : j’étudie comment les partis traditionnels en Europe s’engagent sur ce thème phare de l’extrême-droite. Pour cela, je travaille sur le corpus construit en commun avec Malo (PartySoMe, Party Social Media). Ensuite, je cherche à savoir si les prises de position de ces partis traditionnels en matière d’immigration peuvent expliquer leur déclin dans les urnes. Pour cela, j’intègre la mesure obtenue (c’est-à-dire une position plus ou moins favorable à l’immigration) dans un modèle de statistiques inférentielles.
Selma Sarenkapa : Pour moi, une première étape a été de collecter les archives de presse écrite de deux pays, l’Allemagne et la France (12 journaux depuis 1995, ce qui correspond à trois millions d'articles environ). Ensuite, après le nettoyage du corpus, j'ai entraîné un modèle à détecter et classifier automatiquement certains groupes sociaux tels que les femmes, les immigrés et les investisseurs. Dans une deuxième étape, je cherche à savoir comment ces différents groupes sont dépeints dans les médias : sont-ils mentionnés de manière positive ou négative ? Et dans quel contexte (sur quels thèmes portent les articles) ? Pour cette étape, il va peut-être falloir des allers-retours entre approches non supervisées et supervisées [voir encadré] : voir d'abord ce que le modèle propose comme thèmes et si cela fait sens, et si ce n’est pas le cas, revenir à une approche supervisée.
Ces méthodes utilisent des modèles informatiques pour analyser automatiquement des textes. Elles peuvent se classer en deux catégories selon le moment où le chercheur ou la chercheuse intervient dans l’interprétation (autrement dit, selon le type de données fournies au modèle, labellisées ou non). Le domaine a progressé ces dernières années grâce à l'apparition de Large language models (LLM) comme BERT ou GPT qui sont pré-entraînés sur la base de quantités énormes de textes. Ces modèles, développés pour un usage générique, peuvent ensuite être ajustés pour une tâche spécifique aux analyses (fine-tuning).
Les méthodes supervisées
Cette catégorie de machine learning consiste à faire reproduire les analyses par un algorithme à partir des données d’entraînement fournies par le chercheur ou la chercheuse. Il peut s'agir d'entraîner un modèle à classer des unités (par exemples des phrases d'un article, des titres de projet de loi, etc.) selon un critère pertinent pour répondre à une question de recherche. Un échantillon du corpus catégorisé manuellement sert au modèle à apprendre quelles caractéristiques du texte correspondent à quelles catégories, afin d’en déduire les catégories des autres textes. Après des étapes d’ajustement (tests de validité suivis d’une augmentation du nombre de cas traités manuellement sur un sujet mal prédit par le modèle), le ou les modèles sont capables d’annoter l'ensemble du corpus. L’analyse de sentiment est un exemple d'utilisation d'un modèle de classification supervisée où la catégorie que l’on cherche à prédire est le type de sentiment.
Au CEE (en plus des thèses abordées dans le texte principal), ces méthodes sont pratiquées par Emiliano Grossman au sein du Comparative Agendas Project pour coder les thèmes abordés dans les programmes (il a été pionnier avec d'autres pour développer l'approche), et aussi dans le cadre du projet UNEQUALMAND, dirigé par Isabelle Guinaudeau et impliquant Selma Sarenkapa. Dans un article à paraître, Ronja Sczepanski propose avec un collègue un outil de détection automatique et d’extraction des mentions de groupes sociaux dans des textes politiques.
Elena Cossu, avec Jan Rovny et Caterina Froio, utilise ce type de méthodes pour analyser les dynamiques idéologiques néo-autoritaires et illibérales à l’échelle de l’Union européenne, tant du côté des élites que des citoyens politisés (projet AUTHLIB). Ils s’appuient notamment sur des modèles BERT supervisés pour catégoriser automatiquement des tweets, des manifestes électoraux et des communiqués de presse de partis, dans le but d’identifier et de comparer les expressions discursives de l’illibéralisme. Caterina Froio les utilise aussi dans le cadre du projet FARPO pour identifier et coder automatiquement les protestations impliquant des acteurs d’extrême droite. Le projet RESPOND supervisé au CEE par Cyril Benoît et impliquant Sebastian Thieme, implique du scraping à grande échelle de sites gouvernementaux et des algorithmes de classification des lois. De façon similaire, le projet KNOWLEGPO (Matthias Thiemann et Jérôme Deyris), a nécessité l’aspiration de grandes quantités de texte en ligne, puis la mobilisation de LLM pour classifier les façons dont les membres de la Federal Reserve présentent dans leurs délibérations et leurs discours les causes de l’inflation ou la politique fiscale.
Les méthodes non supervisées
L'objectif est aussi de classer des unités en différentes catégories, mais l'approche est inductive et non déductive. Les modèles de langage proposent des clusters sur la base de similarités / dissimilarités de langage entre plusieurs unités, sans que l’utilisateur détermine à l'avance ce qui doit être recherché.
Selma Sarenkapa essaie par exemple de faire émerger des thèmes à partir des données sans a priori plutôt que d’en imposer (topic modelling) : elle a ainsi fourni à un modèle des phrases mentionnant des groupes sociaux spécifiques afin d'obtenir une liste de thèmes. Sur cette base, elle a ensuite regroupé ces thèmes afin de créer une liste plus restreinte de thèmes spécifiques à chaque groupe, qu’elle a pu utiliser pour entraîner (de manière supervisée) un nouveau modèle. Jérôme Deyris utilise des méthodes similaires, pour explorer les différentes façons qu’ont les banquiers centraux de parler de changement climatique dans leurs discours publics.
Elena Cossu, avec Jan Rovny et Caterina Froio, dans le cadre du projet AUTHLIB, mobilise également des approches non supervisées, telles que l’annotation automatique par des modèles de langage de grande taille (comme LLaMA), afin d’extraire et de structurer des catégories discursives liées à l’illibéralisme directement à partir des données, sans recourir à un codage manuel préalable.
Vous avez organisé fin 2024 les journées d’études doctorales annuelles du CEE intitulées cette année Using computational methods to study political competition. Pourquoi ce choix ? Qu’en avez-vous retiré ?
Selma : Nous avons réalisé que nous étions plusieurs à utiliser des méthodes assez similaires. L'idée était donc de rencontrer d’autres doctorantes et doctorants de différentes universités qui utilisent aussi ces approches pour étudier des sujets liés à la compétition politique et à la polarisation dans la communication politique, sur les médias sociaux, dans les médias traditionnels, dans les politiques publiques. L’objectif était de faciliter un échange productif d'idées sur les travaux de doctorat de chacun.


Luis : Nous avons invité des doctorants et doctorantes que l'on connaissait déjà et d’autres qu'on ne connaissait pas encore : cela permet de créer du réseau. Cela nous a aussi permis de faire savoir qu’à Sciences Po, il existe tout un groupe de personnes s’intéressant aux Computational Social Sciences, avec bien sûr le medialab [représenté lors de ces journées], mais pas uniquement.
Meryem : Au-delà des présentations de travaux de thèses, qui ont montré différentes méthodes à différents stades d’avancement, soulevé différentes questions, je retiens aussi les échanges avec des chercheurs et chercheuses senior comme Alex Kindel (medialab), qui est venu rappeler l’importance de la validité constructive (capacité d’un modèle à refléter ce qu’il est supposé mesurer) et de la validité prédictive (capacité à prédire des résultats futurs), Jan Rovny qui a insisté sur l’importance d’une base théorique solide et Ronja Sczepanski qui est intervenue sur la publication en sciences sociales computationnelles.


Malo et Luis, vous avez donné en janvier un cours intersemestre intitulé Computational Social Sciences qui a eu beaucoup de succès et qui est reconduit en juin. Avec quel objectif avez-vous monté ce cours ? Qu’ont appris les étudiantes et étudiants de l’Ecole de la recherche qui l’ont suivi ?
Malo : L'objectif de ce cours était de former des étudiantes et étudiants qui ont déjà des bases en programmation, pour aller un peu plus loin que ce qui est abordé en master. Avec Luis, nous nous sommes formés seuls, mais nous pensons que c'est quelque chose qui devrait faire partie de la formation à la recherche aujourd'hui à Sciences Po. En une semaine, nous avons proposé un panorama de ces techniques, montrant comment on part d'une question de recherche, ce qu'on cherche à mesurer dans des textes, comment on construit son corpus, comment collecter des données en ligne, jusqu’aux avancées les plus récentes matière d’analyse, avec tout ce qu’impliquent l’intelligence artificielle et les Large Language Models (comme BERT, ChatGPT, etc.) Nous avons abordé chaque jour un type de méthode : méthodes supervisées, méthodes non supervisées [voir encadré], comment convertir des données textuelles en représentation numérique pour pouvoir ensuite les traiter avec des méthodes statistiques, etc.


Luis : Nous avions structuré le cours en trois sessions chaque jour : une première session d’apports théoriques, une deuxième faisant la démonstration d’exemples de codes informatiques, et une troisième session pour faire pratiquer les étudiantes et étudiants à partir de cas pratiques que nous avions préparés. Par exemple, nous leur avons proposé d’annoter des textes de façon collaborative, avec 20-30 textes à coder chacun, qui ont ensuite servi à entrainer un modèle pour leur montrer comment cela fonctionne.
L’avantage de ce format d’une semaine, c’est que les étudiantes et étudiants sont repartis avec une compréhension globale des différents concepts et méthodes, leurs avantages et inconvénients, et des scripts qu’ils peuvent réutiliser. Mais une semaine aussi intense ne laisse pas forcément assez de temps aux participantes et participants pour développer leurs projets. Or, il y en a un certain nombre qui soit viennent avec des projets en tête, soit réalisent au cours de la semaine ce qu'ils pourraient faire avec ces méthodes en lien avec leurs intérêts de recherche. Proposer un cours sur un semestre permettrait de mieux accompagner ces projets.
En tout cas, c’était un plaisir de voir cet engouement (nous avons même dû créer une liste d'attente à un moment donné). Cela montre qu’il y a une vraie demande, en complément des deux cours sur R que nous donnons respectivement en premier et deuxième semestre de master.

Quelles sont les limites de ces méthodes d’analyse computationnelles ?
Luis : Il y a des tâches sur lesquelles ces méthodes sont moins performantes : si l’on cherche à mesurer un concept qui est compliqué à expliquer (et à détecter systématiquement, même par des humains), la méthode aura beau être aussi avancée et sophistiquée, cela ne marchera pas. Si l’on choisit une méthode supervisée, il faut que le concept qui nous intéresse soit bien défini.
Malo : L'utilité des méthodes supervisées, c'est de pouvoir mesurer des concepts de sciences sociales dans de larges corpus de données. L'avantage vient vraiment avec le volume de données parce que le but, c'est d'automatiser quelque chose qui prendrait beaucoup plus de temps si on le faisait manuellement de A à Z. Il faut donc aussi se demander si notre volume de données est suffisant pour nécessiter ce type de méthode.
En fait, la question est celle du temps disponible et de l'implication qu'on a envie de mettre dans une telle tâche, et la réponse varie selon les personnes. Un chercheur senior avec un budget conséquent pourrait payer 30 assistants de recherche pour leur faire analyser 50 000 textes manuellement. Mais comme je suis un doctorant avec un temps limité pour faire ma thèse et personne pour travailler pour moi, l'arbitrage va être différent.
Y a-t-il d’autres précautions à prendre ?
Luis : Il y a des questions éthiques, mais qui sont celles que se posent aussi d’autres collègues manipulant d’autres types de données : où sont stockées les données ? Selon la nature des données collectées, peut-on les confier aux serveurs d'OpenAI ou de Google, ou doit-on le faire en local, sur notre machine ?
Malo : En revanche, une particularité de la plupart des données que nous traitons avec ce type de méthodes, c’est qu'elles n'ont pas été initialement produites pour la recherche. Certes, nous les collectons et les mettons en forme pour pouvoir les analyser mais nous n’en sommes pas à l’origine. Au contraire des entretiens qualitatifs ou des enquêtes par sondage, où les personnes interrogées savent que c’est dans un objectif de recherche et donnent leur accord pour cela, nous, nous récupérons des textes et des données qui sont produits dans un but complètement différent de ce pour quoi on les utilise. Si on parle de données venant d’applications, on n'est pas allé demander aux personnes utilisant ces applications si elles acceptaient que leurs données soient rendues accessibles sous tel ou tel format. Donc, cela pose des questions en termes de mise à disposition [au reste de la communauté académique] des données utilisées et de réplicabilité de la recherche.
Luis : Enfin, l’utilisation des grands modèles de langage présente des coûts énergétiques et des impacts environnementaux importants.
L’intelligence artificielle, le machine learning, sont des domaines qui évoluent vite : comment voyez-vous le futur des sciences sociales computationnelles ? Et l’utilisation croissante de l’IA générative dans la création de contenus modifie-t-elle vos corpus ?
Meryem : Lors des journées d’études que nous avons organisées, Étienne Ollion (sociologue, directeur de recherche CNRS) est justement venu présenter un travail récent répondant à la question : « L’IA générative peut-elle imiter les humains pour répondre à des enquêtes d’opinion ? » Avec d’autres collègues, il montre que les réponses proposées par des bots de type ChatGPT sont biaisées, et que ce biais varie selon les thèmes abordés.
Malo : Les avancées les plus récentes concernent le traitement de l'audio ou de l'image ou même de ce qu'on appelle du multimodal (analyse simultanée de l’image et de l'audio ou du texte). Par exemple, si l’on cherche à analyser des débats parlementaires, il peut être intéressant de collecter aussi bien le contenu des discours mais aussi les gestes, le ton…
Meryem : Au-delà de l'audio et des images, est-ce que l’utilisation de l’IA générative va influencer les textes, les sources, les corpus, avec un langage peut-être plus standardisé ? Est-ce que, maintenant que les outils d’analyse se démocratisent, les documents vont devenir plus faciles à extraire et analyser ou au contraire, certains acteurs vont-ils rendre les données plus compliquées à obtenir ou en monétiser l’accès ?
Luis : Si les modèles sont entraînés sur des textes créés par ChatGPT, qui ne sont pas toujours de bonne qualité, ces modèles risquent de perdre en performance. On pourrait voir apparaitre un cercle vicieux : des contenus générés par l'IA, sur lesquels on entraîne les modèles d’IA servant à créer d’autres contenus, etc.
Pour terminer, quels seraient vos conseils aux personnes qui souhaitent se lancer dans les sciences sociales computationnelles ?
Malo : Toutes les tâches que l’on a évoquées (scraping, nettoyage des données, analyses), on doit les coder. Donc c’est sûr qu’à un moment, il faut accepter les mains dans le cambouis, si je peux dire. Mais avec un niveau de base en statistiques et des notions de programmation, je trouve qu'on peut rapidement comprendre les principales méthodes et l'utilisation qu'on peut en faire. Et aujourd'hui, avec des outils comme ChatGPT, on peut aussi générer du code. Bien sûr, il faut savoir l'utiliser, comprendre ce qu'il nous dit et dans quelle mesure c'est ce qu'on veut. Mais par rapport à il y a deux, trois ans, le coût d'entrée a quand même diminué très fortement.
Selma : Ces méthodes deviennent aussi de plus en plus accessibles parce que de plus en plus de gens partagent ce qu’ils font [par exemple sur GitHub, voir en fin d’article], proposent des formations, publient des articles scientifiques sur leurs méthodes, à l’image de Ronja Sczepanski chez nous : cela devient donc plus facile de savoir comment ça fonctionne.
Luis : Même si l’on souhaite ensuite travailler à la main et ne pas faire d’analyses quantitatives, il est possible d’automatiser tout ce qui en amont de l’analyse, et notamment la collecte des données à grande échelle : au lieu de télécharger à la main un millier de documents PDF depuis un site, un script écrit en deux minutes permet de le faire en une seule intervention. De la même manière, on peut automatiser des copier-coller fastidieux. Pour les personnes qui réalisent des entretiens et doivent les retranscrire, on peut évoquer aussi des outils de transcription automatique basés sur l’intelligence artificielle, comme Whisper ou Notta. De plus en plus de logiciels rendent les méthodes beaucoup plus accessibles.
Propos recueillis par Véronique Etienne.
Merci à Meryem Bezzaz, Malo Jan, Selma Sarenkapa et Luis Sattelmayer pour leur temps, ainsi qu’à Yuma Ando et Isabelle Guinaudeau qui ont contribué par leurs explications ou leur relecture.
Pour aller plus loin
Comment le big data révolutionne les sciences sociales, par Nonna Mayer (Article The Conversation)
- Programme des journées d’études Using computational methods to study political competition (décembre 2024)
- Cours intersemestre Computational Social Sciences
- Pages Github de Malo Jan, Luis Sattelmayer, Selma Sarenkapa
- Pages HuggingFace de Malo Jan, Luis Sattelmayer, Selma Sarenkapa
Autres personnes et projets du CEE qui utilisent le machine learning dans leurs recherches :
- Personnes : Yuma Ando, Elena Cossu, Jérôme Deyris, Caterina Froio, Isabelle Guinaudeau, Emiliano Grossman, Ronja Sczepanski
- Projets : AUTHLIB, KNOWLEGPO, RESPOND, UNEQUALMAND
À Sciences Po, au-delà du CEE :
- MetSem, un séminaire de méthodes, co-organisé par les ingénieures et ingénieurs des différents centres de recherche de Sciences Po (dont Yuma Ando du CEE)
- MetAt, un atelier mensuel d’accompagnement aux méthodes de recherche, coordonné par les ingénieures et ingénieurs du medialab
- L’Institut libre des transformations numériques, dont l’une des thématiques prioritaires concerne les traces numériques pour les sciences sociales